How the DOM constructs webpages incrementally

Understanding the DOM and how it's constructed is the cornerstone of performance optimization.
One of the longest, top-level tasks that takes place on the main thread is the Parse HTML task. This task represents the HTML parser constructing what we refer to as the Document Object Model (DOM). Before a page loads, most performance bottlenecks can be traced back to this process.
Document Object Model
The DOM is a web API that connects the code we write to the code in the browser. It's one of the most common web API's used in web development.
Sometimes you might hear the DOM referred to as "document" or "document tree" instead of "document object" or "the DOM".
If I open up the Google Chrome devtools console and type document, we'll see HTML which is similar to the html in our file that the browser downloaded.
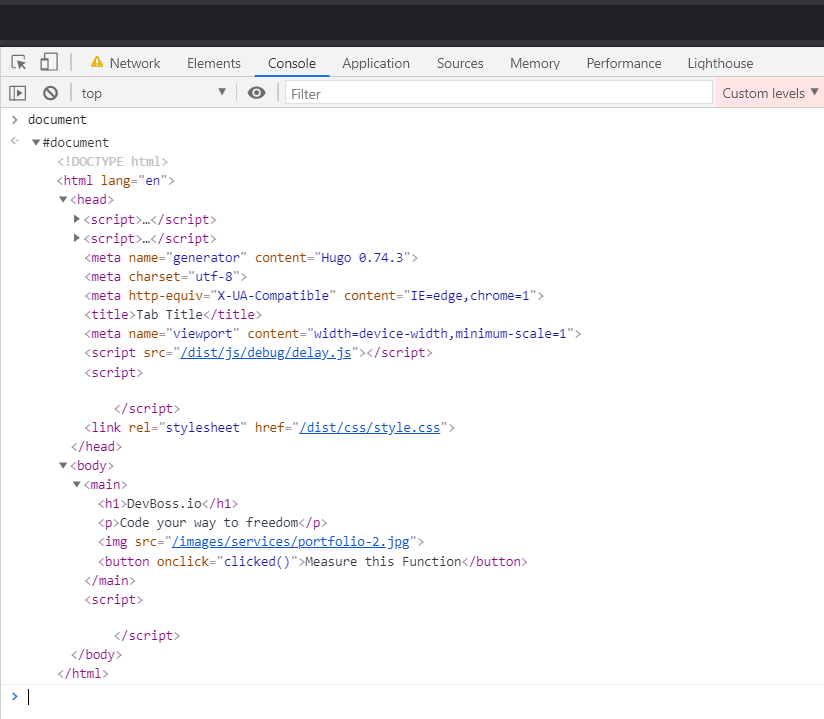
If I type console.dir(document), I can output the document in it's full object form.
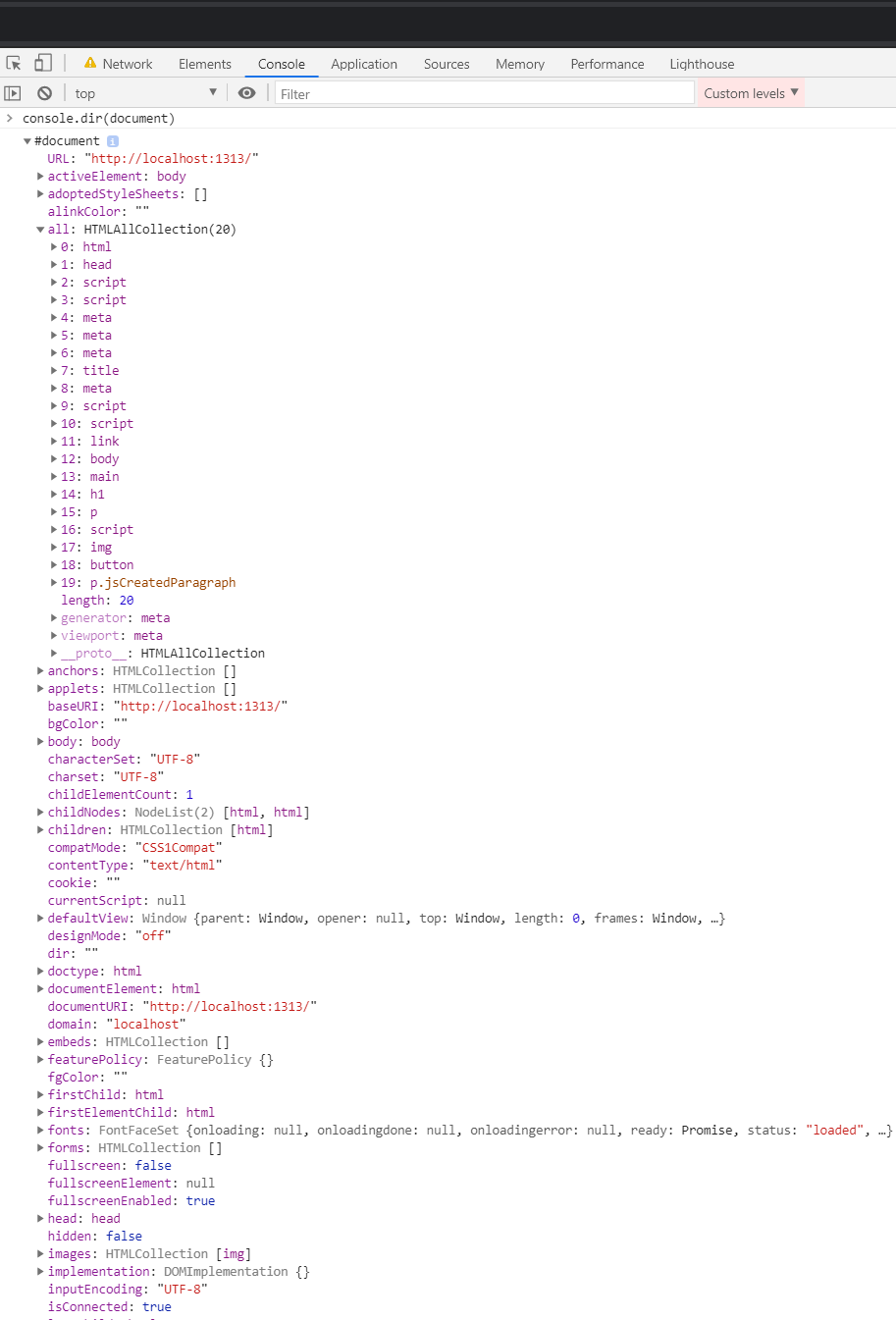
The DOM is literally an object containing many other objects and it is initially constructed from the HTML in our index.html file. That HTML contains references to JavaScript and CSS, which also contribute to the construction of the DOM.
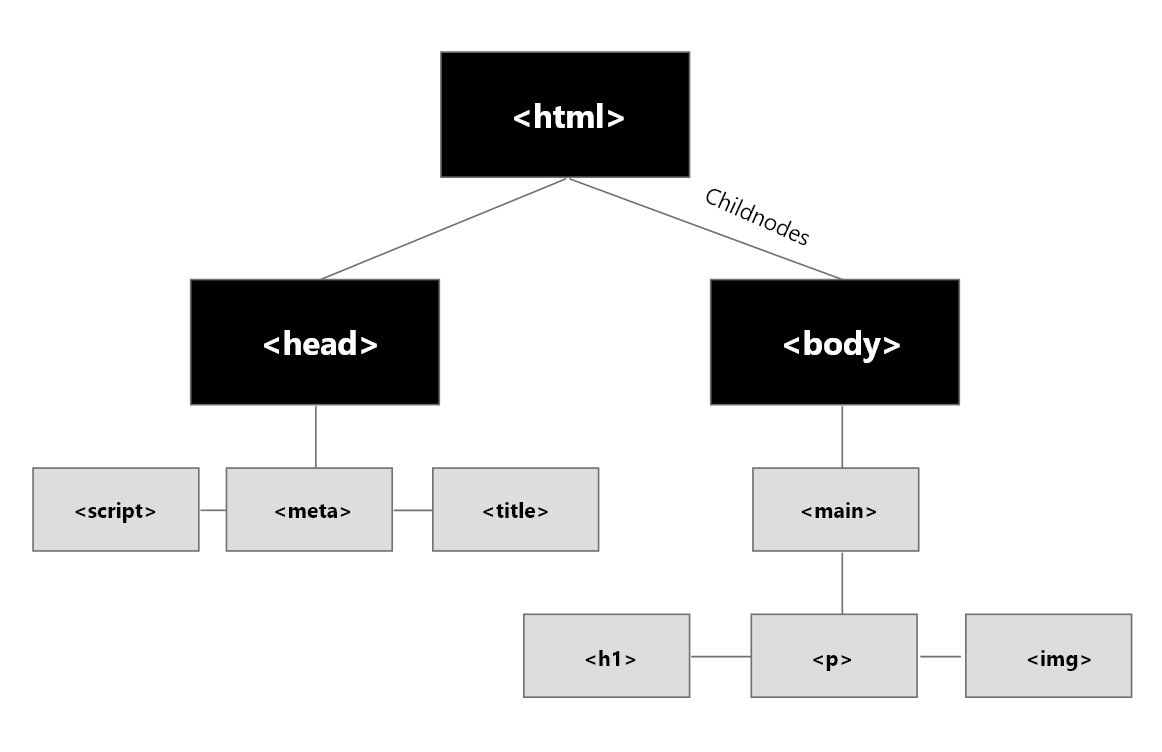
The DOM is a relational tree where each branch of the tree ends in a node and each node contains objects.
DOM/HTML Parser
When you visit a webpage in your browser, the first file that gets downloaded is the HTML file for that page.
After the download finishes, the DOM parser or HTML parser is responsible for parsing the string in our HTML file and building the document object.
// Parser sees:
"<html>...</html>"
// Not HTML nodes
<html>...</html>
The DOM parser evaluates the HTML from the top down and from parent to child.
<html lang="en">
<head>
<script></script>
<meta name="generator" content="Hugo 0.74.3">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>Tab Title</title>
<meta name="viewport" content="width=device-width,minimum-scale=1">
<link rel="stylesheet" href="/dist/css/style.css">
<script src="/dist/js/debug/delay.js"></script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/fetch-inject.umd.min.js"></script>
<script></script>
</head>
<body>
<main>
<h1 class="nodeAfter">Heading</h1>
<img alt="" src="https://images.pexels.com/photos/5272985/pexels-photo-5272985.jpeg?cs=srgb&dl=pexels-julia-volk-5272985.jpg&fm=jpg">
</main>
<script></script>
</body>
</html>
Given this source HTML, the DOM Parser will discover each HTML node starting at the outer most node (HTML) and working through each child node from the top down.
- html
- head > script > meta > meta > meta > title > meta > link > script > script > script
- body > main
- main > h1 > img
- script
The object representation of each HTML node found by the parser (in order) can be found via document.all.
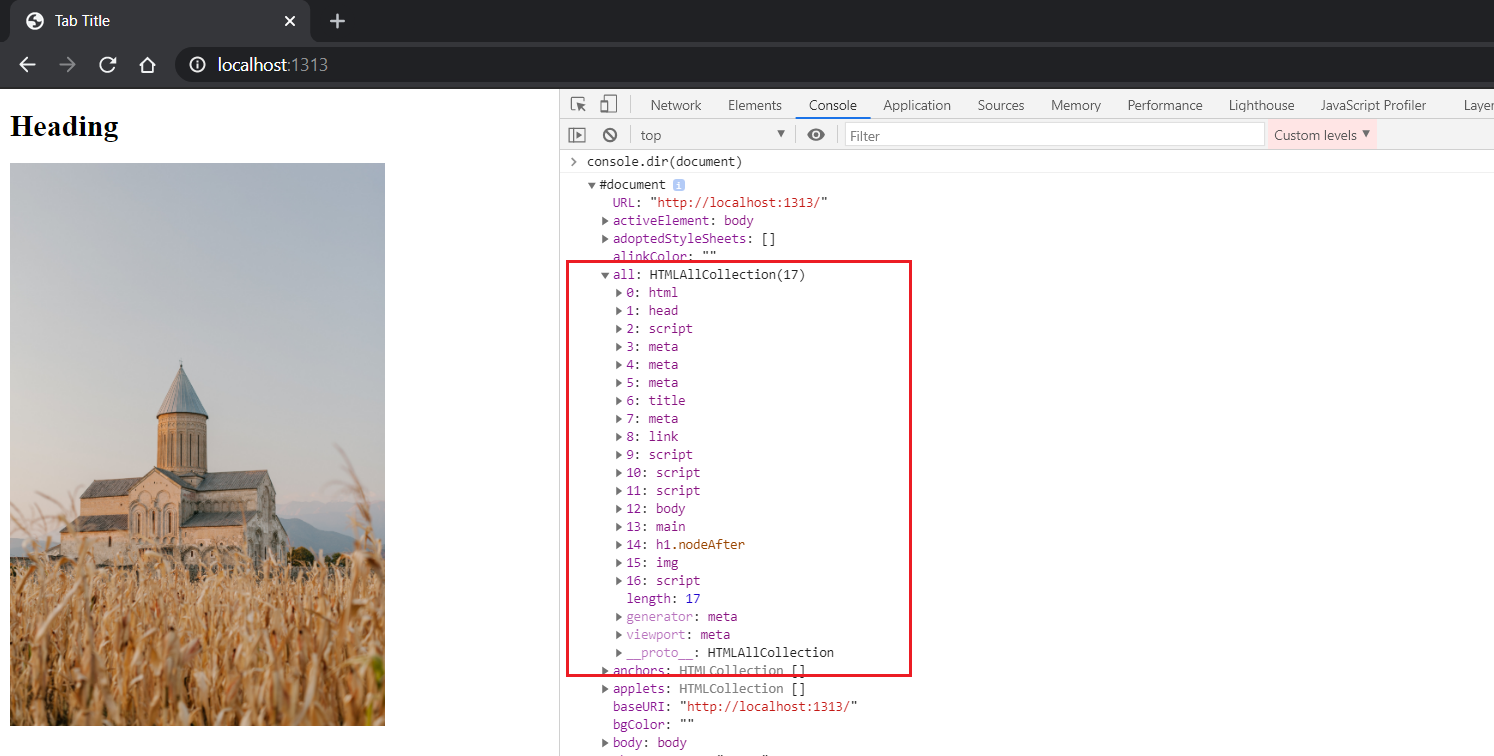
Tracking DOM Construction time
We can track how long the DOMParser takes to fully evaluate our HTML file and build the DOM.
The
Like we discussed in the
Dev Tools Network Tab Dev Tools Performance Tab MutationObserver and event listeners
We will primarily use the
Impact of Resource Downloads on DOM Construction
A resource is another file that is referenced from our HTML. Images, stylesheets, JavaScript, fonts, and JSON are the most common resources linked to from an HTML document.
These referenced resources are discovered and downloaded in the order that they are found by the HTML parser.
...
<head>
...
<title>Tab Title</title>
<link rel="stylesheet" href="/dist/css/style.css" />
<script src="/dist/js/debug/delay.js"></script>
<link rel="stylesheet" href="/dist/css/style_large.css" />
<script src="/dist/js/hello.js"></script>
<script src="/dist/js/hello_large.js"></script>
<link rel="stylesheet" href="/dist/css/one.css" />
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/fetch-inject.umd.min.js"></script>
<link rel="stylesheet" href="/dist/css/two.css" />
<link rel="stylesheet" href="/dist/css/three.css" />
</head>
<body>
<main>
<link rel="stylesheet" href="/dist/css/four.css" />
<script src="/dist/js/hello_again.js"></script>
...
Resources are downloaded in the order that the DOM Parser discovers them in.
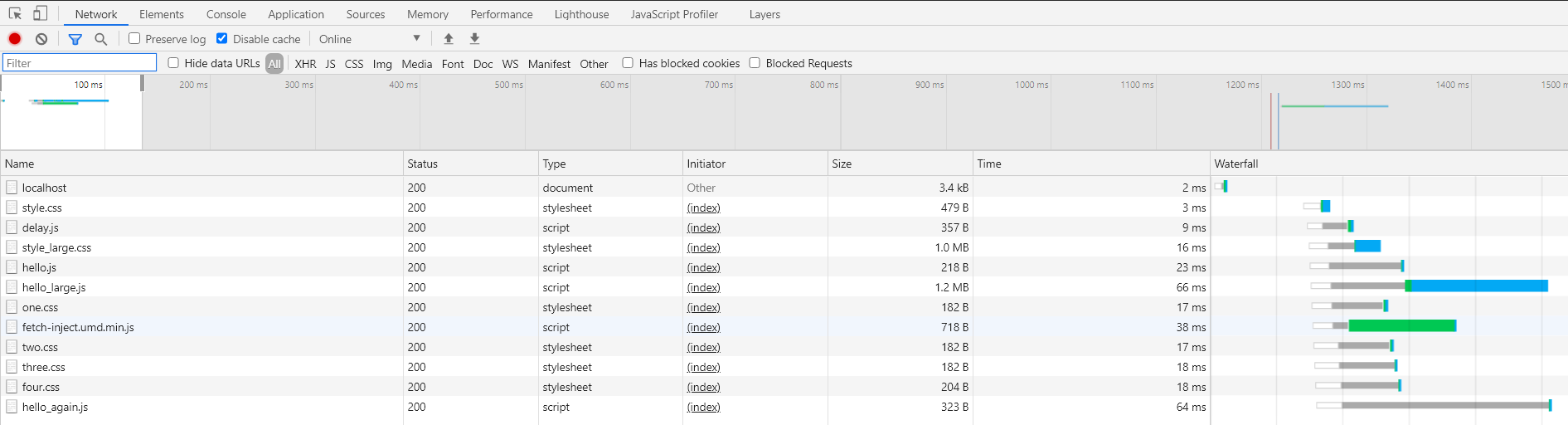
Parallel Resource Downloads
Multiple resource downloads can occur simultaneously. Resources, even of the same type, do not depend on a previous resource to finish downloading before the next resource of the same type starts downloading.
There's latency associated with each request and there's also the time it takes the user's internet connection to download the file. If your internet connection is fast or you're developing locally, you should
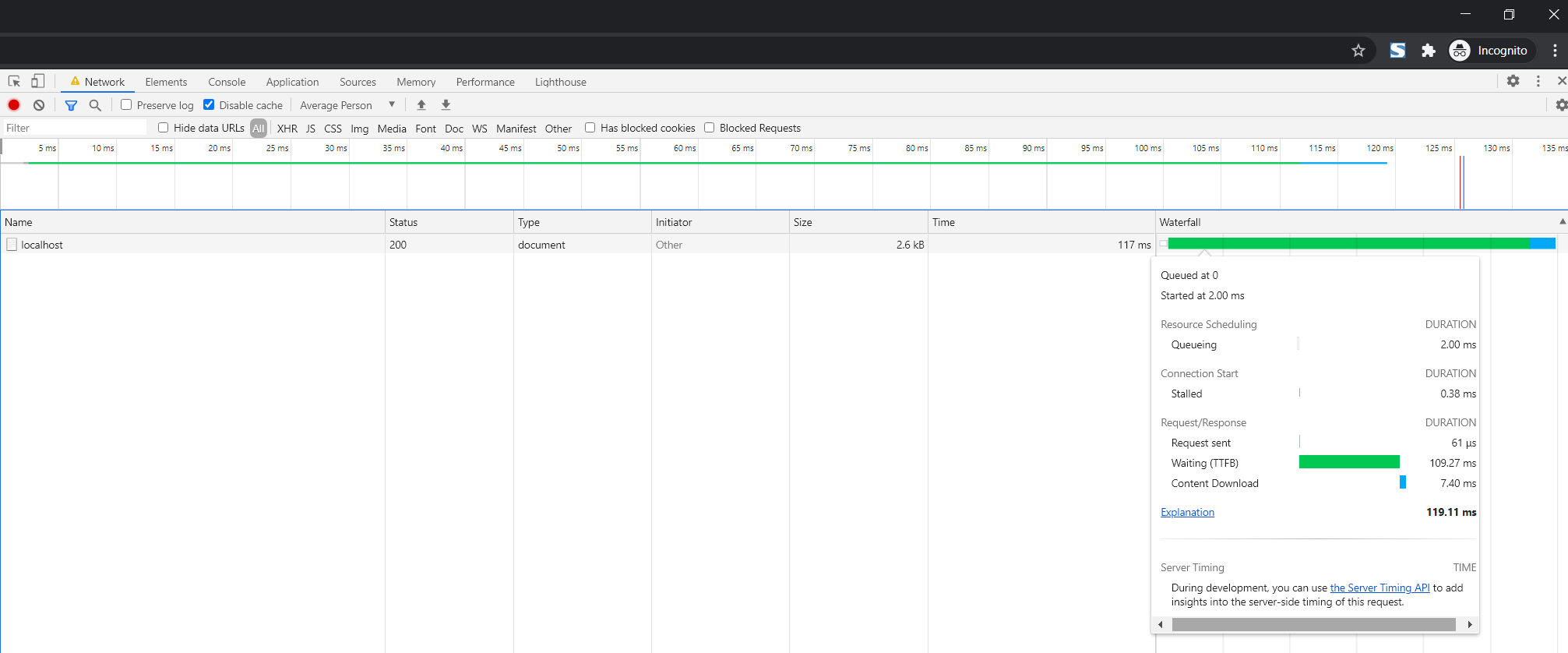
If we hover over a network request, we can see more information related to the download time.
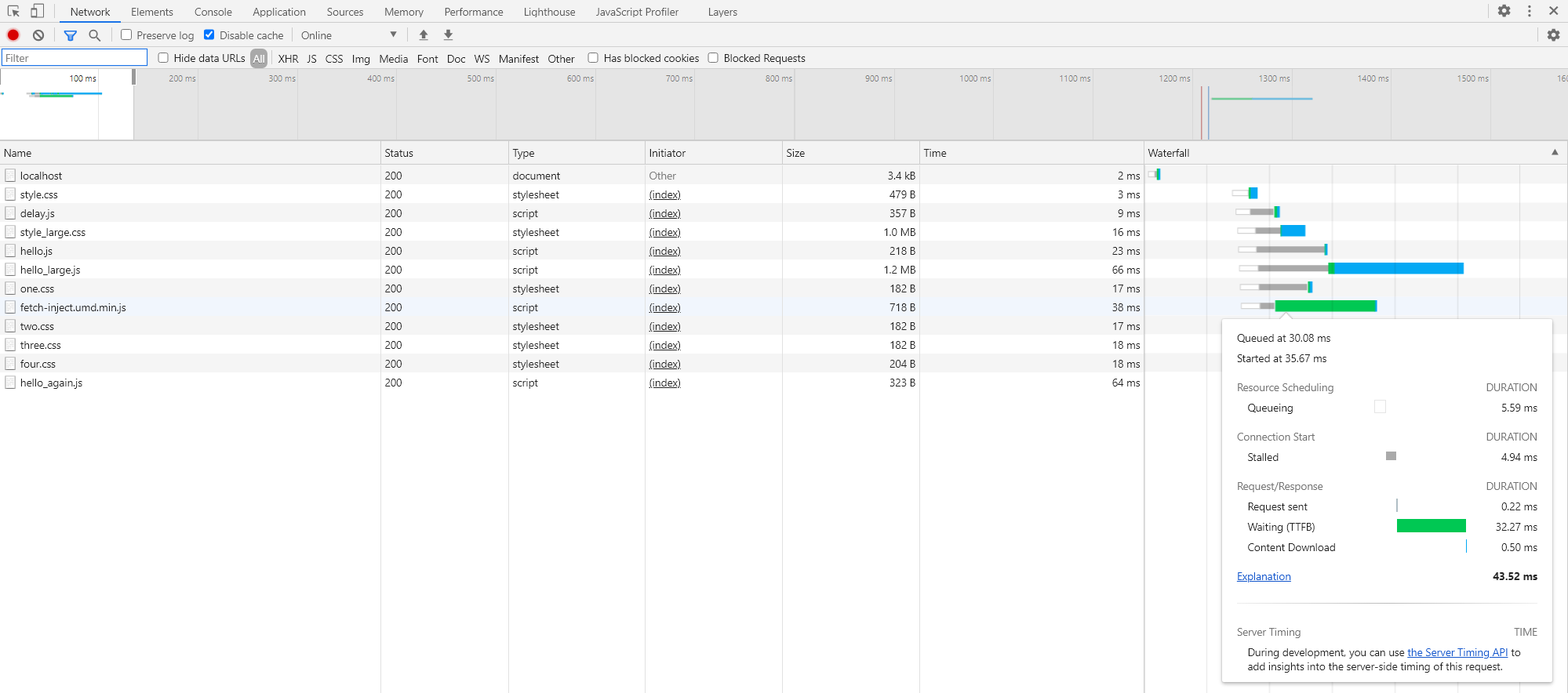 Download time depends on a few factors: the time it takes to communicate with the server and download the file (internet connection speed and download size).
Download time depends on a few factors: the time it takes to communicate with the server and download the file (internet connection speed and download size).
The number of parallel downloads that can occur simultaneously depends on the server's HTTP protocol and the user's internet connection.
CSS/JS Resource Downloads can pause DOM construction
When we link to these resources in the standard way, (using a typical script src= or link href=), the download time can delay DOM construction and discovery of subsequent nodes.
We can see this with the MutationObserver.
If we add a large script after the image tag, the Time Since Last Node Added increases from 0 to 3268.
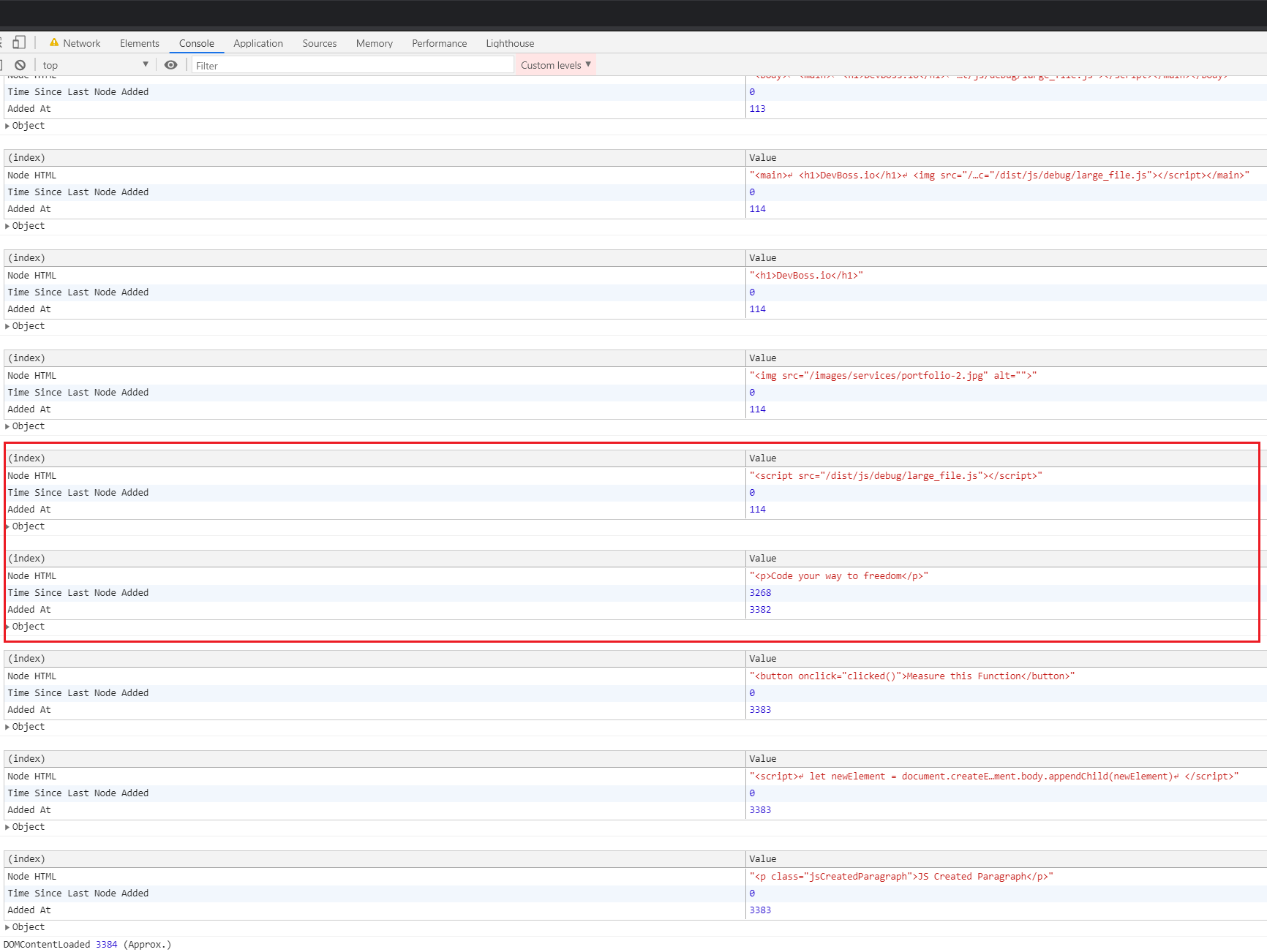
Looking at the network tab, we can see that this script took about that long to connect to the server (latency) and download the file.
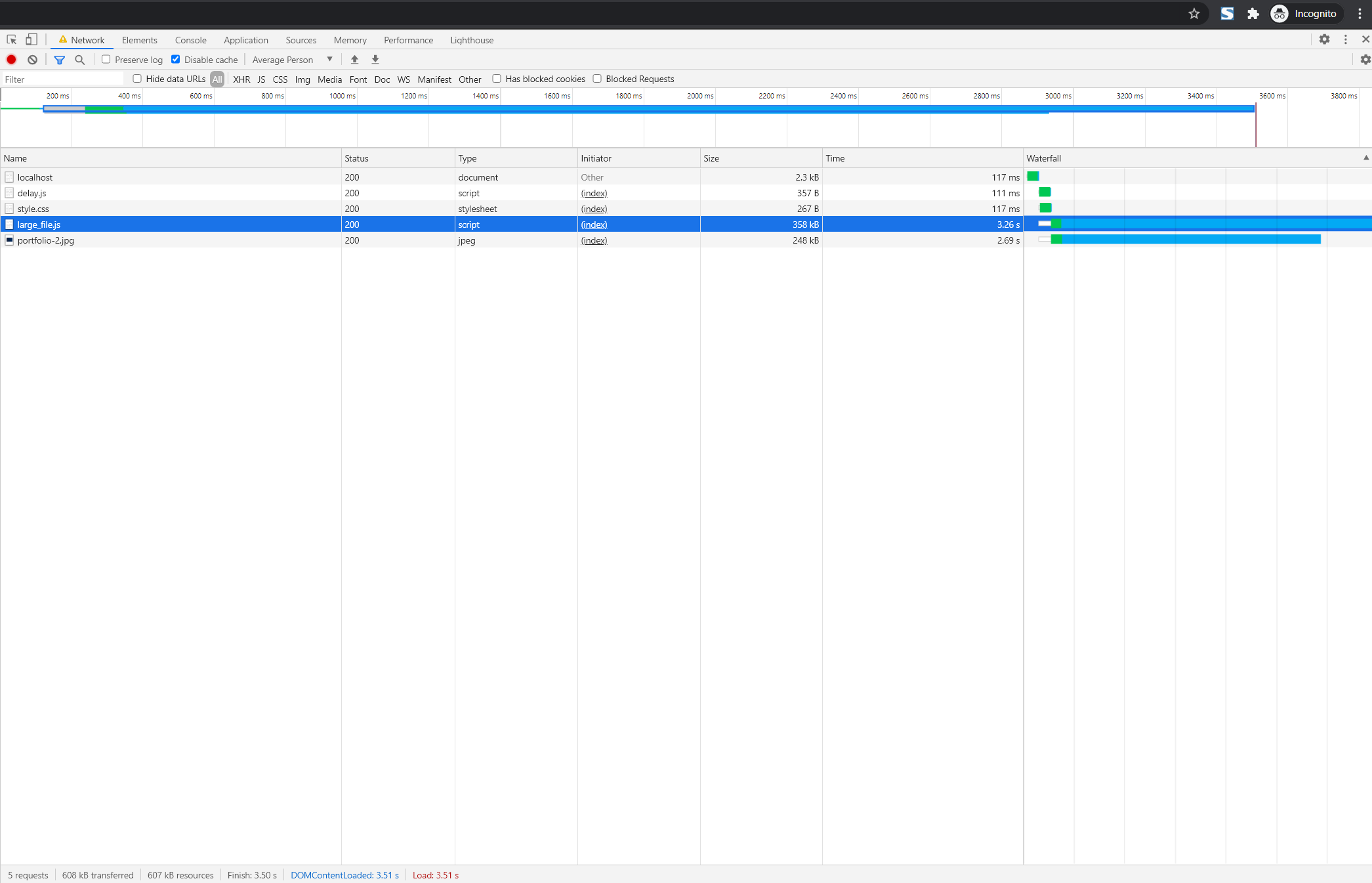
Note that DCL increased from 1.95s to 3.51s
Speculative Parsing
So we know that if we include a large JS or CSS file the HTML parser stops building the DOM tree and discovering nodes for at least the download time of that resource (at a minimum). However, modern browsers have accounted for this situation and use a feature called speculative parsing to queue these downloads before the DOM Parser discovers those script or link nodes.
Consider the following source code:
<script src="/dist/js/hello_large.js"></script>
</head>
<body>
<main>
<h1 class="nodeAfter">Heading</h1>
<script src="/dist/js/hello_again.js"></script>>
...
The hello_large.js is just a large file containing comments only (no JavaScript). Since JS download time can pause the DOM Parser, we would expect a delay in the discovery of the <h1 class="nodeAfter">Heading</h1> and <script src="/dist/js/hello_again.js"></script> in the <main> section.
As a result, we should expect our network tab to show that the first script discovered by the DOM Parser (hello_large.js) downloads before the script discovered later by the parser (hello_again.js).
However, the network tab shows the opposite behavior.
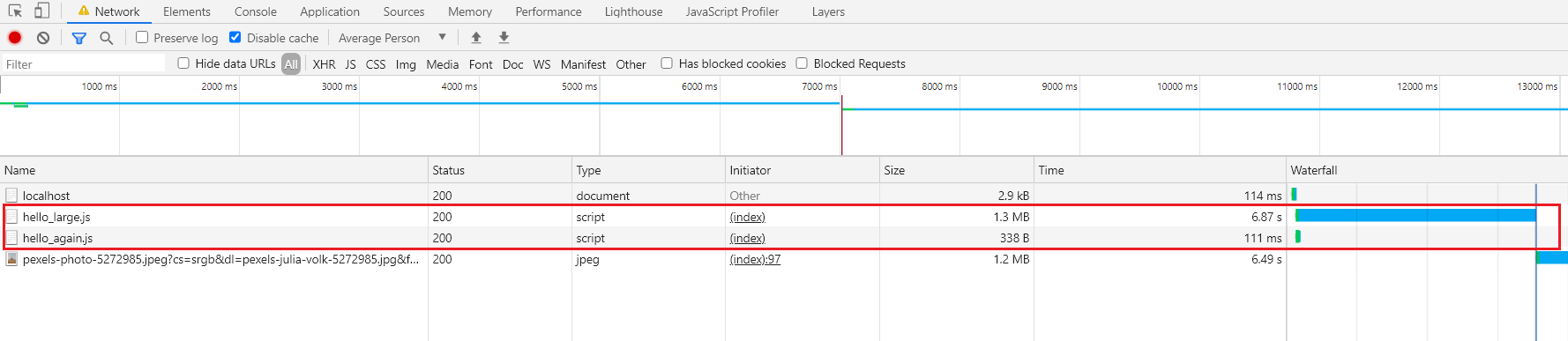 We can clearly see that the
We can clearly see that the hello_again.js file started and finished downloading before the first JavaScript file (hello_large.js) finishes.
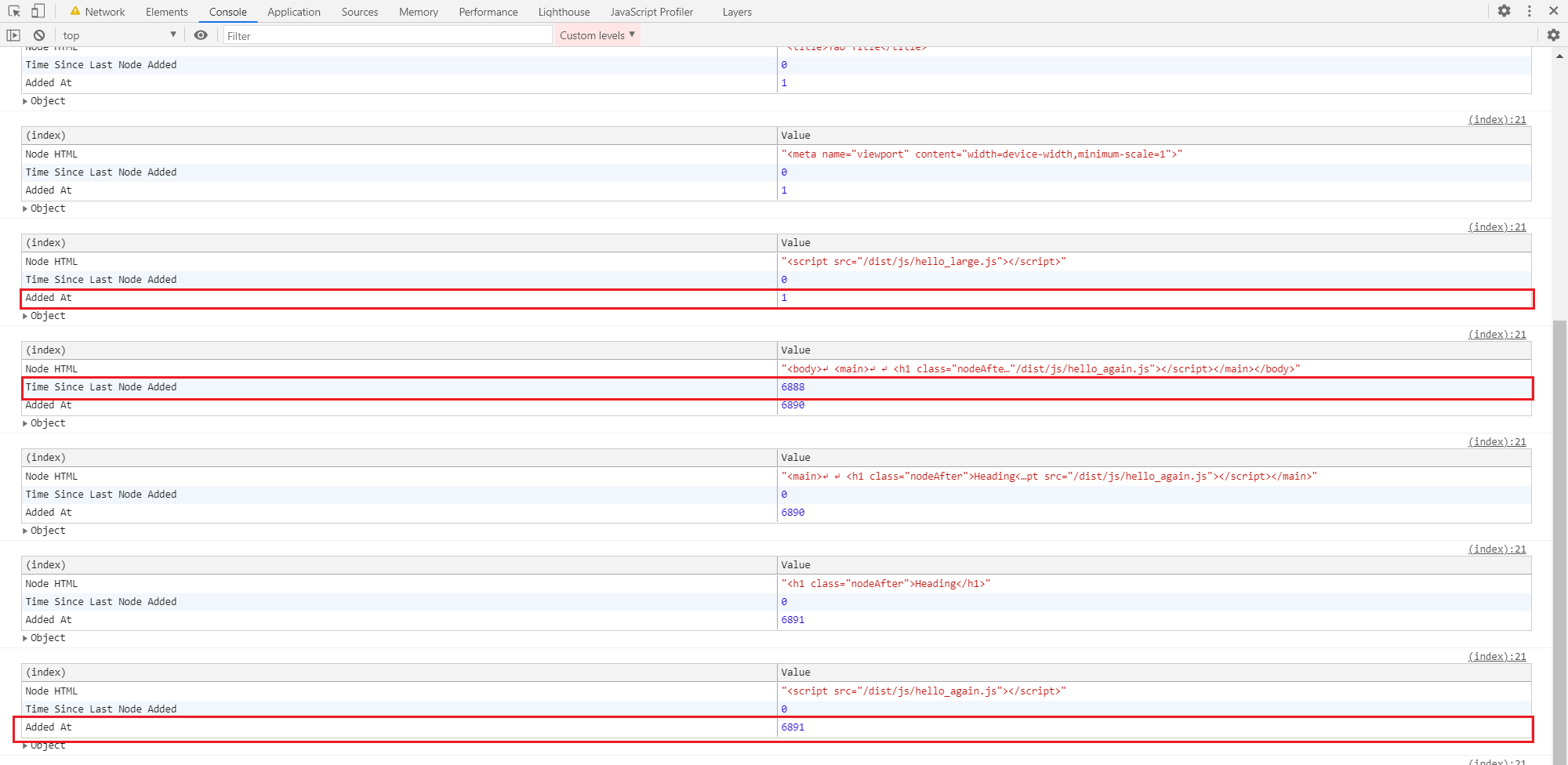
Additionally, the MutationObserver shows what we would expect: the DOM Parser was paused during the download of the first JS file. hello_again.js isn't added to the DOM until 6890, but the download started and finished at 111ms.
Speculative parsing only applies to the queueing of the resource download. The actual execution of code doesn't occur until it's discovered by the DOM Parser. This can be illustrated by including a console.log("HELLO!") in our hello_again.js file.
 Even though this file finishes downloading at less than 200ms, the JavaScript code doesn't execute until the DOM Parser discovers the HTML that links to the resource - almost 7 seconds into the loading process.
Even though this file finishes downloading at less than 200ms, the JavaScript code doesn't execute until the DOM Parser discovers the HTML that links to the resource - almost 7 seconds into the loading process.
Tracking Speculative Parsing Time
There's no official metric for how long the speculative parser takes to discover the resources and queue them. However, we can get a general idea of how long this process takes by comparing the end of the initial HTML download to the start of the queued resources.

How JavaScript Impacts DOM Construction
The HTML of our DOM is different from the page source. The document HTML is the HTML after the DOMParser constructs the document from the initial pagesource.
 Page source.
Page source.
The DOM contains the HTML after JavaScript runs because the DOMParser executes JavaScript when it's constructing our DOM tree.
console.log(document)
Side note: If you use a JS framework like Vue or React, you might see the source of the page as only containing a <div id="app"></div> while the actual document contains lots of HTML. This is because these frameworks create the HTML using JS. This JS is executed during DOM construction.
Pausing construction to execute JS
When the parser encounters a script tag, it usually pauses construction of the DOM, downloads the script, and then queues the code for execution before continuing construction. In many cases, JS executes as soon as it is discovered by the DOM Parser.
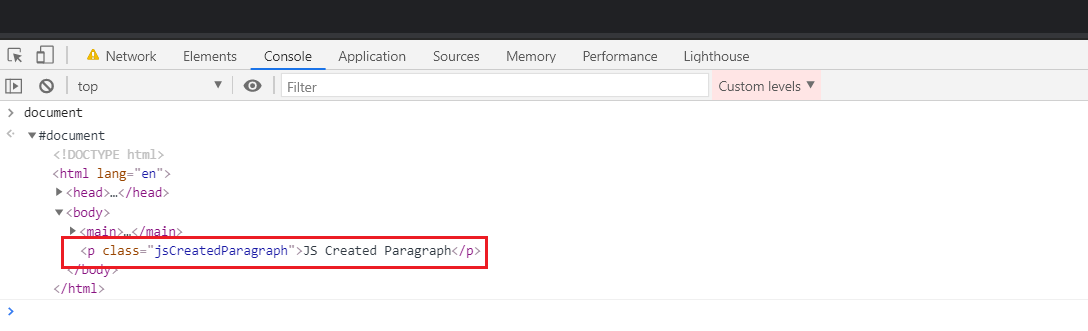
We can confirm this by creating an element with inline JS, and it will show up in our MutationObserver log before the DOMContentLoaded event finishes.
<script>
document.addEventListener("DOMContentLoaded", () => {
console.log("DOMContentLoaded", new Date() - startTime, "(Approx.)")
observer.disconnect();
})
</script>
...
<body>
<main>
<script>
let newElement = document.createElement("p");
newElement.className = "jsCreatedParagraph";
newElement.innerText = "JS Created Paragraph"
document.body.appendChild(newElement)
</script>
</main>
</body>
The MutationObserver logs the inline script and also the node created by the inline script.

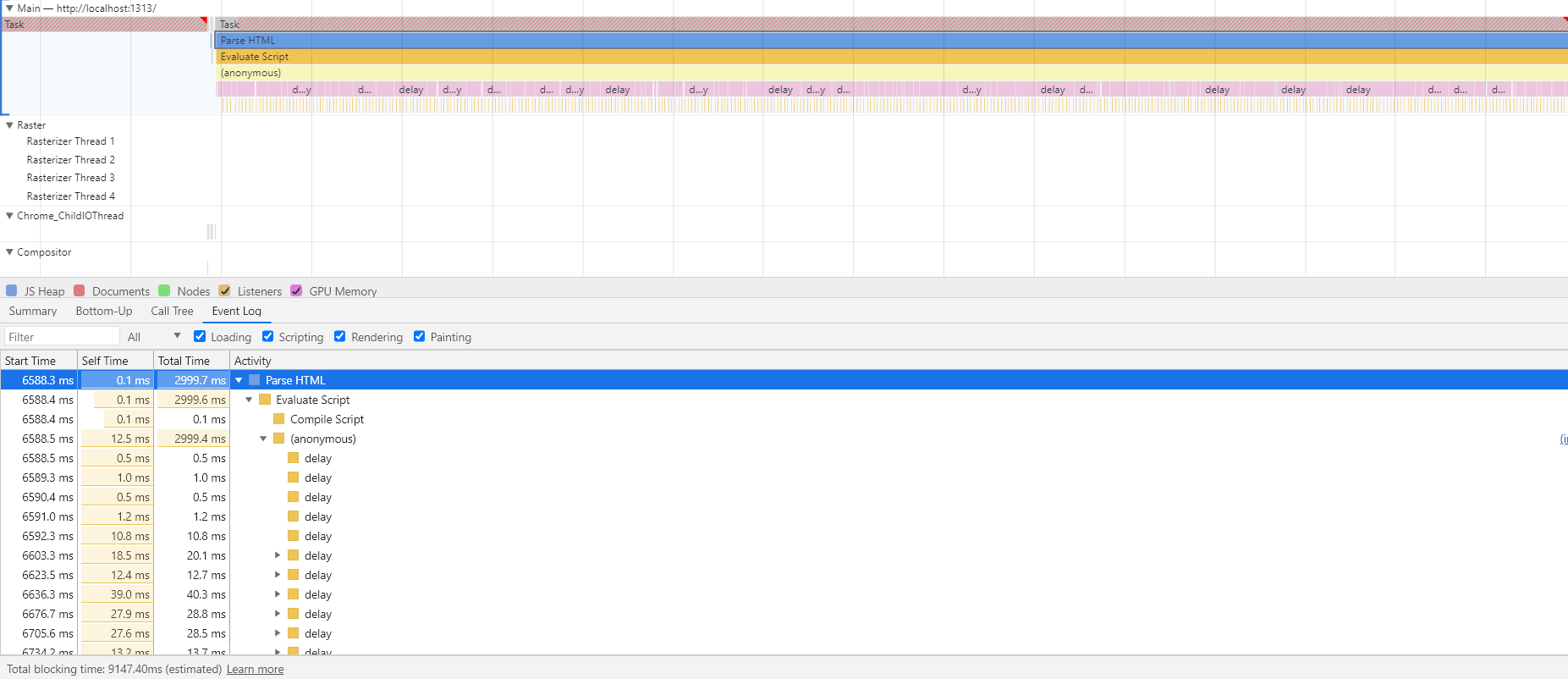
Script Evaluation Impact on Parse HTML Task
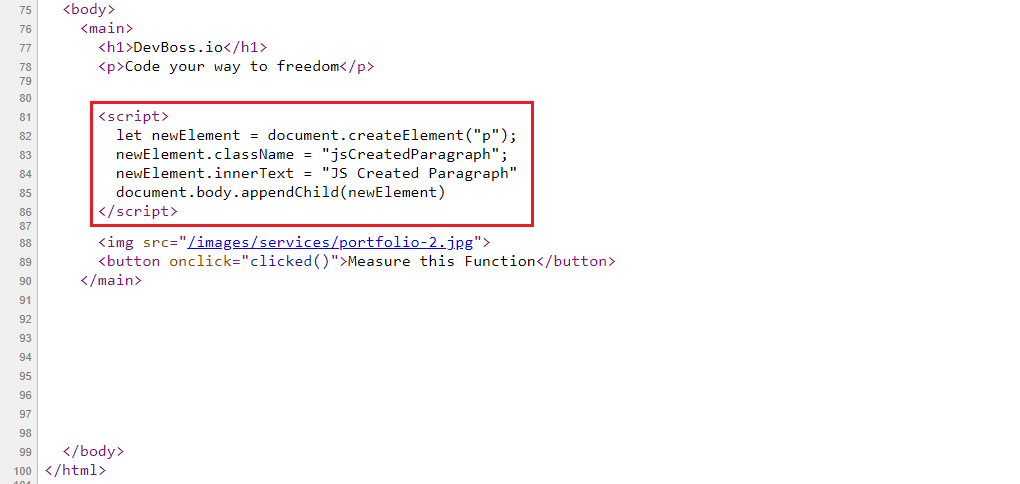
Here I've created a delay(ms) function to simulate poorly optimized code. I can control how long this function takes to finish running by passing the number of milliseconds as the first argument when I call the function
// delay.js
function delay(ms) {
var start = Date.now(),
now = start;
while (now - start < ms) {
now = Date.now();
}
}
When the function is invoked inline, the Script Evaluation task is nested under the Parse HTML task.
<script src="/dist/js/debug/delay.js"></script>
</head>
<body>
...
<h1>DevBoss.io</h1>
<img src="/images/services/portfolio-2.jpg" alt="">
<script>
delay(3000)
</script>
<p>Code your way to freedom</p
...
If we look at the MutationObserver console log, the "Time Since Last Node Added" is 3009ms and our delay function took 3000ms to finish.
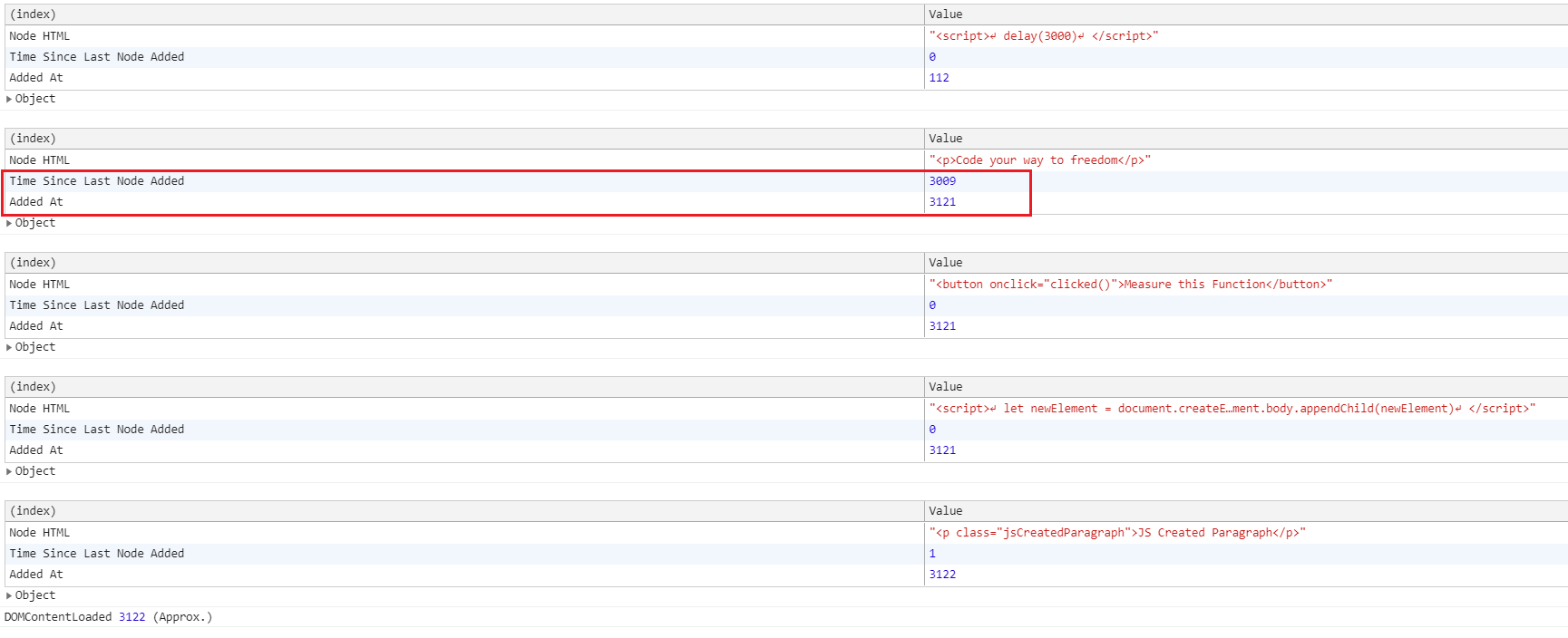 DOM construction is delayed because the delay function must finish executing before the DOM parser continues.
DOM construction is delayed because the delay function must finish executing before the DOM parser continues.
Stylesheets Impact on DOM Construction
When a stylesheet is encountered by the DOM parser, it is downloaded and parsed before continuing DOM construction. Inline styles also pause DOM construction.
Consider a page with a single stylesheet referenced in the <head>:
<html lang="en">
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
<title>Tab Title</title>
<meta name="viewport" content="width=device-width,minimum-scale=1" />
<link rel="stylesheet" href="/dist/css/style_large.css" />
</head>
<body>
...
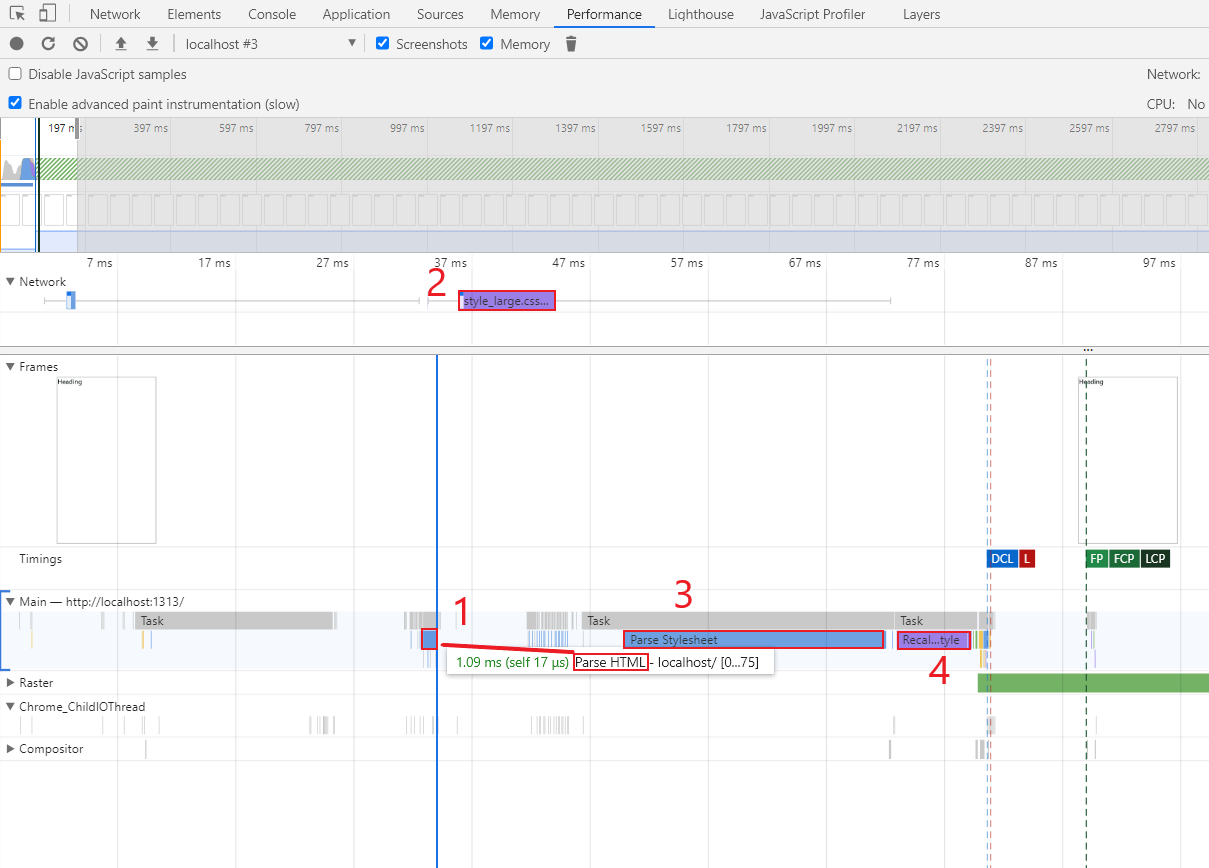
- HTML Parser discovers the stylesheet and pauses DOM construction. "Parse HTML" task stops.
- Stylesheet is downloaded
- The Stylesheet is parsed and the Parse Stylesheet task appears as a top-level task on the timeline
- Styles are recalculated, triggering the following top-level tasks: Recalculate Style > Layout > Update Layer Tree > Paint > Composite Layers
- HTML Parser continues
Inline styles result in a slightly different task flow.
<html>
<head>
...
<script>
function start() {
console.log("start")
}
start()
</script>
<style>
p {
color: red;
}
...
</style>
</head>
...
- HTML parser discovers the
<style>tags inline and paused DOM construction. - The inline styles are parsed as part of the Parse HTML task on the timeline
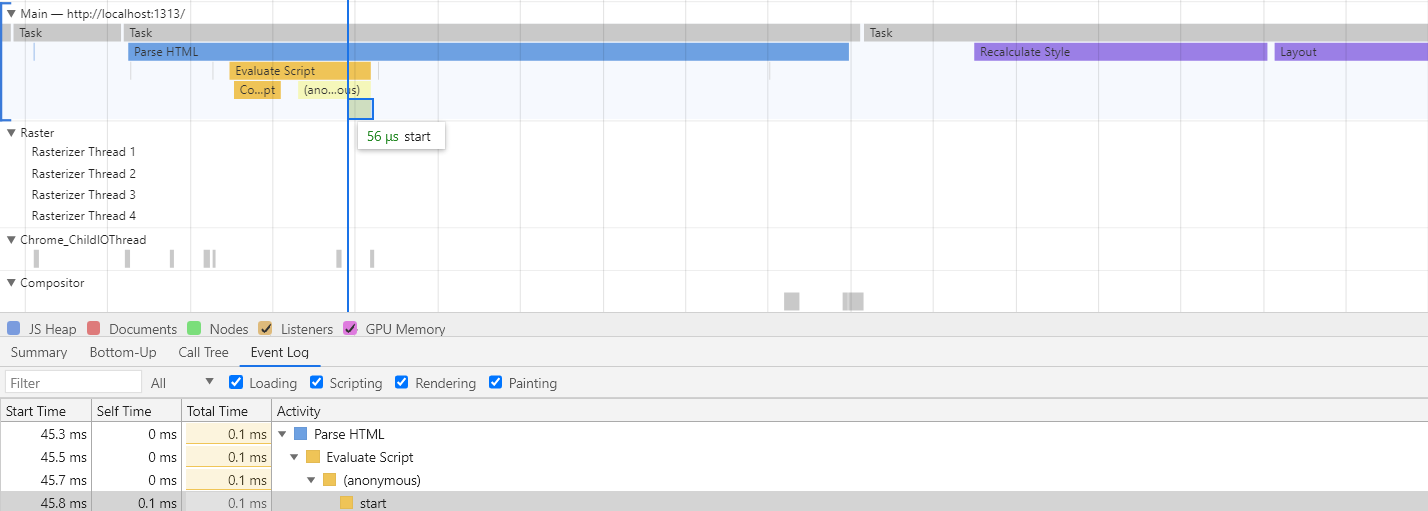
- Then the following top-level tasks occur: Recalculate Style > Layout > Update Layer Tree > Paint > Composite Layers.
The main difference between the task flow of an inline style and an external stylesheet is that there is no network request associated with the inline style and there won't be an associated Parse Stylesheet task. Instead, the parsing process is included in the Parse HTML task.
When the DOM parser encounters CSS early in the DOM parsing process, the associated tasks can significantly delay the HTML parser from constructing the DOM.
Summary
- The HTML of a webpage is the first set of instructions given to the browser.
- HTML Parser (DOM Parser) reads a string (containing HTML) and constructs the DOM (Document Object Model,
Document). - The DOM is the object representation of the webpage and it's an API that allows JavaScript to interact with the page. JavaScript can read and write to the
Documentobject, which can manipulate the page. - DOM Construction occurs incrementally, meaning that the DOM Parser might pause for various reasons.
- The download time for a JS or CSS file can pause DOM construction.
- JS and CSS evaluation can pause DOM construction.
- Image downloading and painting doesn't block the DOM Parser in the same way, but can slow down the overall DOM Construction process.
- A browser can start rendering content to the user before DOM Construction finishes.